
PDF Indexing Filter for native Windows10 applications
PDF Indexing: How-To Inspect and Change the Filter Handlers
First, open the PDF Indexing Options panel in the Control panel:
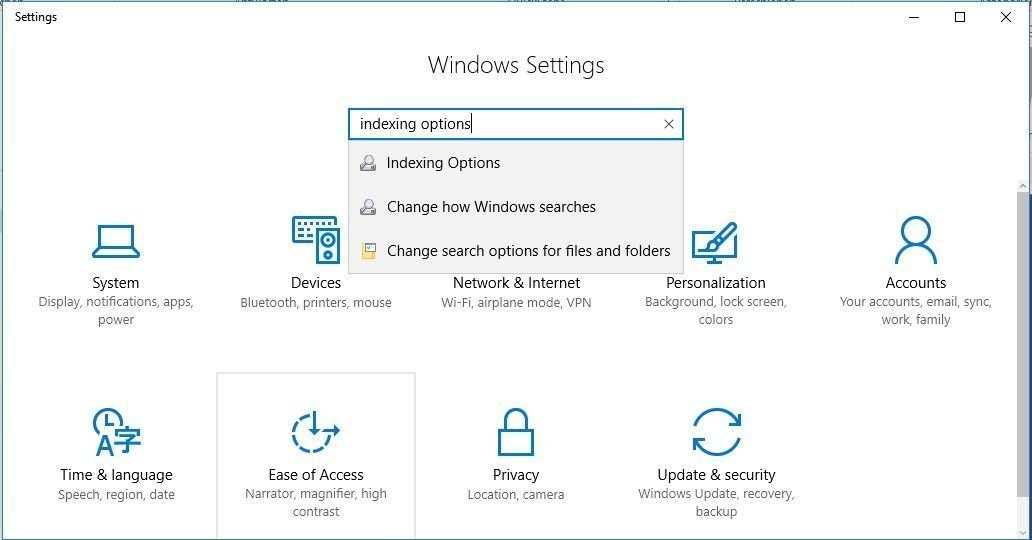
Control Panel for PDF Indexing Options
Now click on Indexing Options / Advanced / File Types. This shows you the list of file extensions and the default Filter Handler registered for it. After installing an Adobe Filter, you can see that it adds a Handler for PDF that it calls “PDF Filter”.

Installed PDF Indexing Filter
Any indexing of PDF content at this point will use the Adobe Filter. To get PDF indexing working with Windows10 Store Universal Windows Platform Apps like Noggle, you need to use the native Windows10 pdf filter which is already shipped with Windows10. To change it, you need to know the GUID for the filter. The please take a note now:
What’s the GUID for the naitive Windows10 UWP PDF Filter?
Adobe GUID: {E8978DA6-047F-4E3D-9C78-CDBE46041603}
Windows10 GUID: {6C337B26-3E38-4F98-813B-FBA18BAB64F5}
That’s great, but now what if you want to switch back and forth?
Default Handlers in the Registry
How do we find out where the Default handler is configured in the Registry? Open the registry editor by typing RegEdit in the windows search box and start the desktop command.
Let’s look at HKEY_CLASSES_ROOT.pdf. In my case, it contains a PersistentHandler sub-key. This GUID is a registry branch that defines the Filter Handler for PDFs.
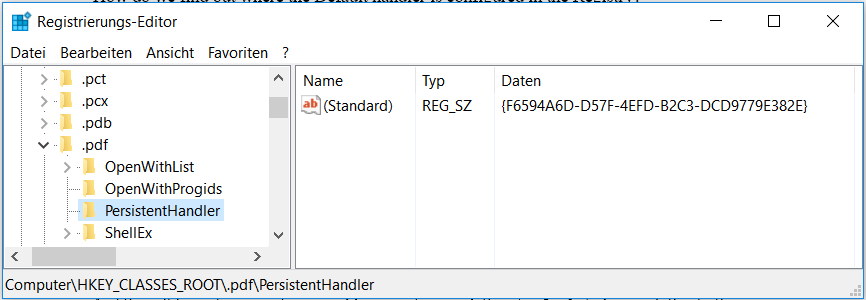
Note: this GUID is not constant like the IFilter GUIDs are. Yours will be different.
So let’s take a look at {F6594…..382E} by searching for it. This brings us to HKEY_CLASSES_ROOTCLSID{F6594…..382E}:
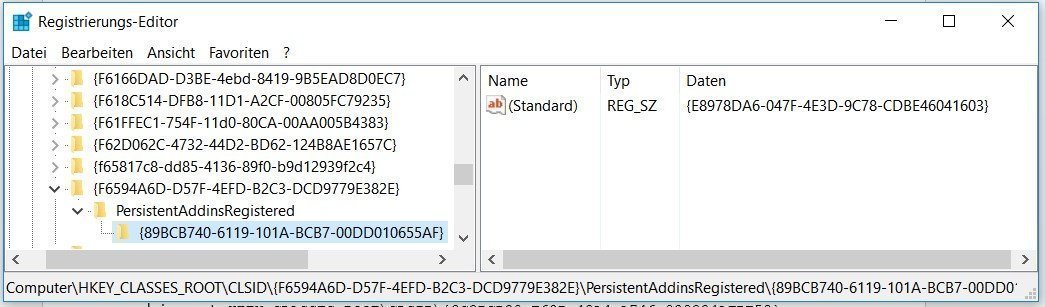
RegEdit PDF Filter Handler
And there it is, under PersistentAddInsRegistered, the (Default or Standard) key pointing to the Adobe GUID of {E8978DA6-047F-4E3D-9C78-CDBE46041603}. As you’ve probably guessed, to change the default handler to the native Windows 10 PDF handler, we just have to replace this GUID with the Windows10 GUID: {6C337B26-3E38-4F98-813B-FBA18BAB64F5}. Let’s try it.
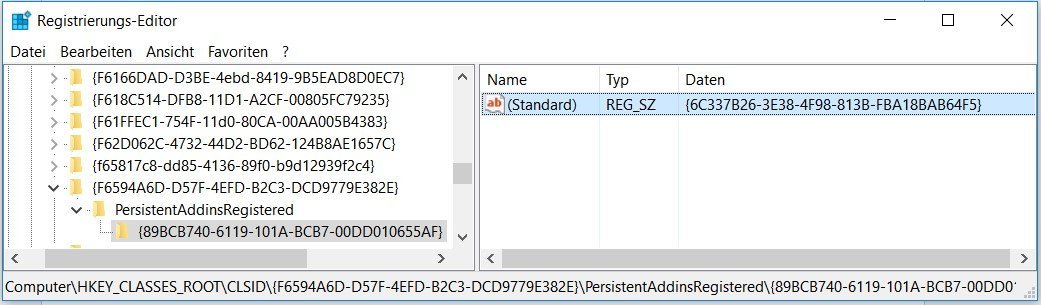
RegEdit PDF Windows 10 IFilter
Now let’s take another look at Advanced Indexing Options:
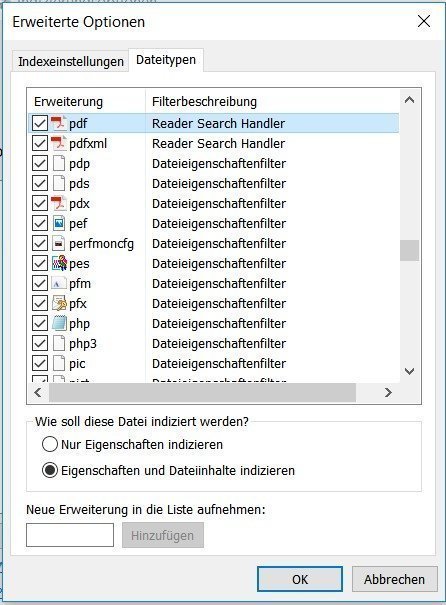
PDF Win10 Filter activated
And we’re on the Windows10 “Reader Search Handler” for PDF indexing with UWP apps. That’s it!
Summary
Here is how the registry entries are structured to define the default or standard handler:
HKEY_CLASSES_ROOT.pdf
PersistentHandler
(Default)={PDF Handler GUID}
|
˅
HKEY_CLASSES_ROOTCLSID{PDF Handler GUID}
PersistentAddInsRegistered
{Some other GUID}
(Default or Standard)={Filter GUID} <– Change this
Finally, you can check if the correct iFilter is available via the SearchFilterView Tool:
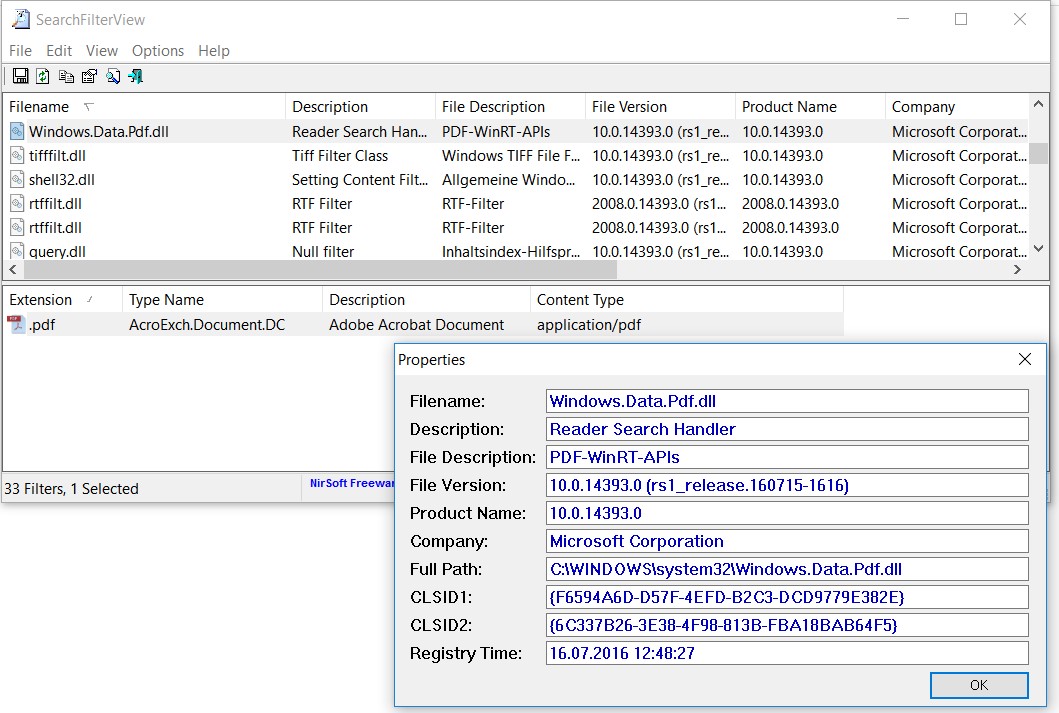
SearchFilterView Tool with correct Windows10 Filter handler activated for the extension .pdf
References:
How To Article for Win7 / Desktop Apps:
Tool to check available filter components:
Technical Info from Microsoft:
https://msdn.microsoft.com/en-us/library/windows/desktop/dd940433(v=vs.85).aspx