[layerslider id=”4″]
Cognitive-guided, non supervised document clustering
NoggleMap Search Document Clustering
One of the most common problems people used to encounter when searching for information is that they could not find documents specifically related to what they were looking for. Nowadays, this task is quite successfully handled by standard search applications.
Thanks to these sorts of search engines, pulling up results has become easy. However, when it comes to explaining the search results or displaying specific details on what sort of results have been returned, users’ options are much more limited. Usually, a search application displays a ranked list of documents and a snippet of their contents. These ranked lists are helpful for document retrieval, but far away from knowledge management. Information about the internal relationships among the documents in the search results is often not provided by standard search algorithms.
Search Document Clustering
“Search result clustering” is defined as an automatic, non-supervised grouping of similar documents in a search hits list returned from a search engine. Clustering is one of many methods that can be used to make searching collections of documents easier.
So, the Noggle “KnowledgeMap,” a search result visualization tool, provides users with essential information about the structure of topics that appear within the search results. Furthermore, the Noggle clustering algorithm scans internal relations and linguistic patterns among all the documents according to how similar they are to the initial search request. This tool can unearth new groups or cross-document relationships, which might guide users to new, interesting areas that build upon their initial search request.
We have often heard users demand such clustered cross-document relationship information, likely because they become frustrated with the constantly growing document volume and fragmented data storage solutions they encounter in the cloud and other big data services.
Problem with ranked search lists
To illustrate the problems with conventionally ranked search result lists, let’s imagine a user wants to find information about “security.” Therefore, he or she starts with the simple search term “security.”
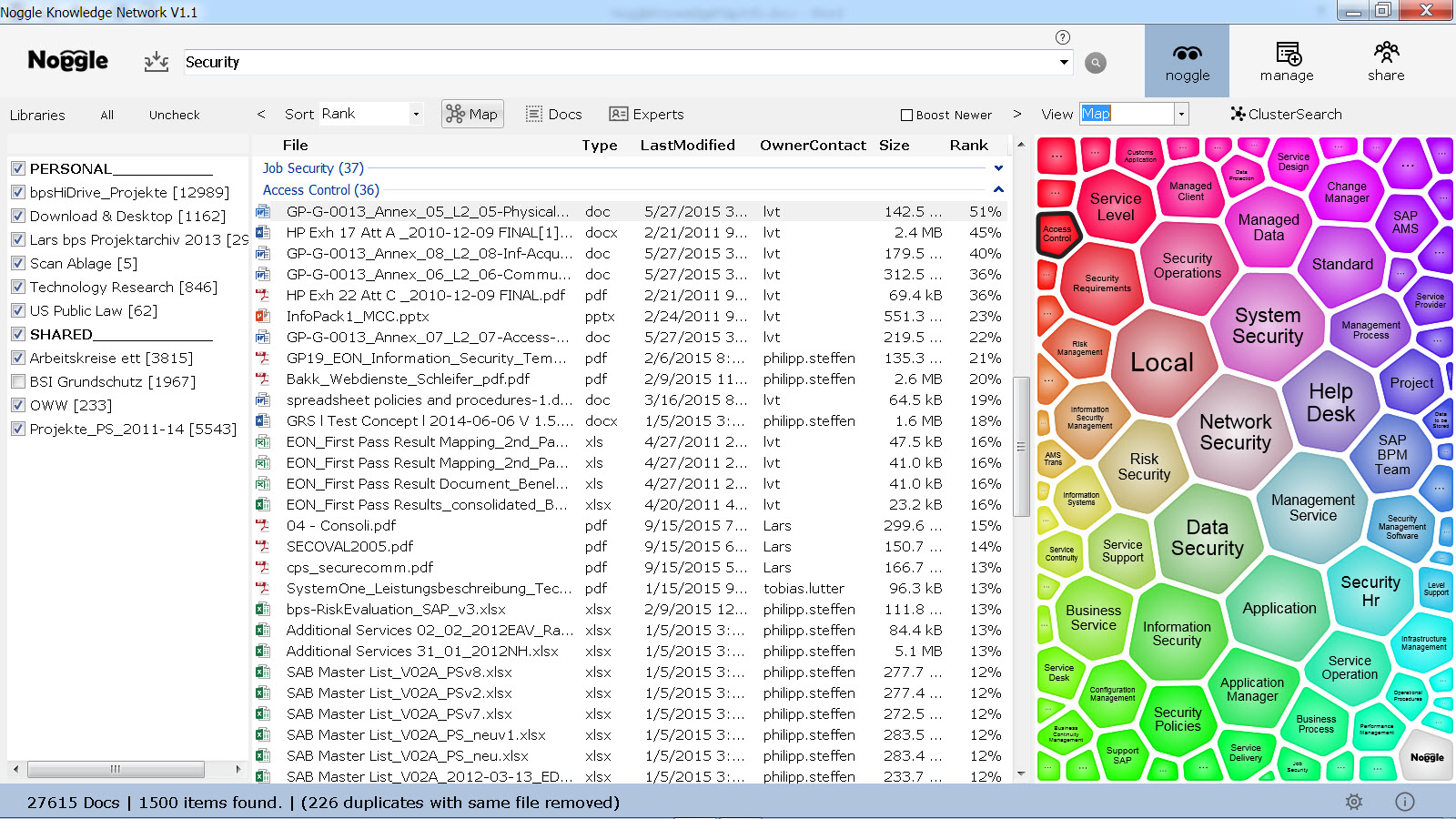
First, the user selects peer libraries that might be relevant. In this example, the user has libraries from three different peers. In addition, the user selects six of his own libraries to perform the search request.
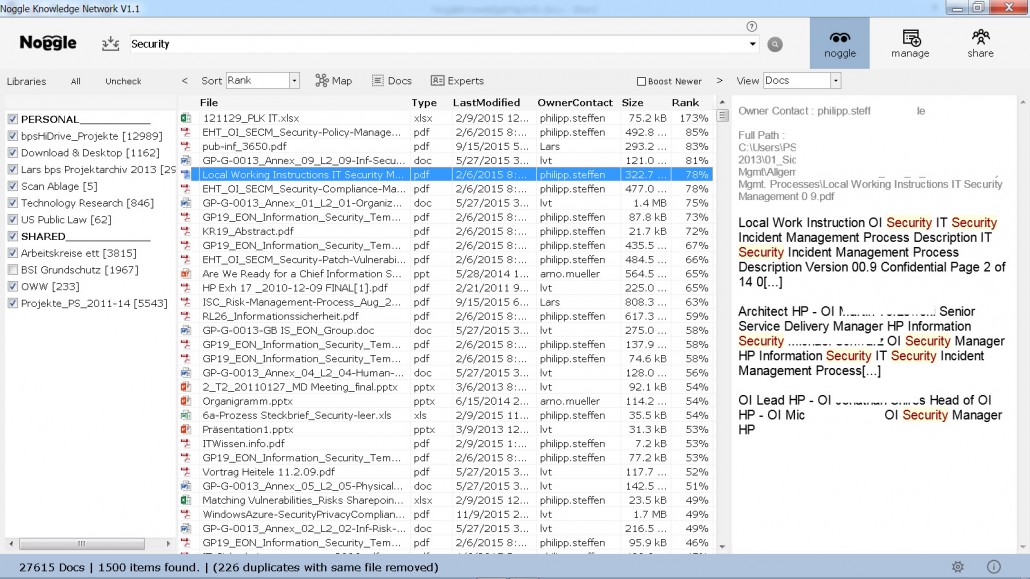
Figure 1: Search results for search term “security” on nine libraries from four different owners
Figure 1 shows that the search included 27,616 documents and returned 1,500 top-ranked documents related to “security.” Obviously, this is a very general query that leads to a large number of hits. Therefore the majority will be about information security, system security, or security policies based on a library for “Information Technology”.
A determined user patient enough to sort through results ranking 100 or lower should be able to find some hits on topics like “access control” or “service continuity.” However, one problem with ranked lists is that sometimes users need to wade through irrelevant documents to get to the ones they want.
Grouping results into semantic cluster via document clustering
But what about an interface that groups search results into separate semantic topics? Like network security, data security, access control, service continuity, and so on? And what if these groups were decided automatically from their own internal content—not by biased methods where someone defines what might be important?
By generating groups like this, the user will immediately get an overview of what the results contain and should be able to pick out relevant documents with much less effort.
The following figure shows how the NoggleMap feature automatically detects cross-document relations based on linguistic patterns. The left part of the screen shows the clusters and the number of documents related to that cluster. The right panel shows a visual representation of that information.
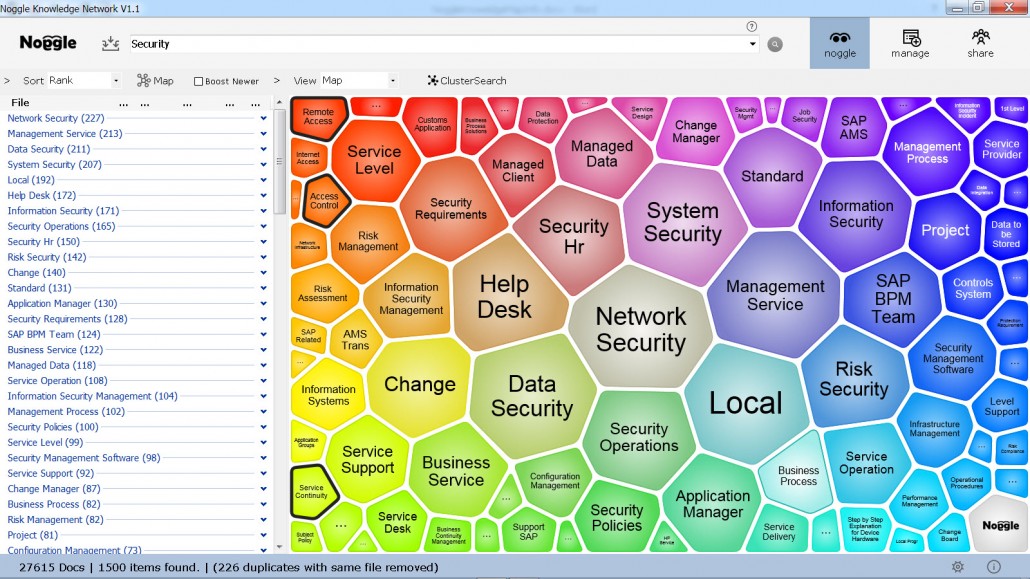
Figure 2: Clustered search results for “security” via the Noggle KnowledgeMap document clustering service
All 1,500 documents are linked to one or more of these clusters. This way, users don’t need to browse through a ranked list from the top down—they can narrow down the major cluster they are looking for and go from there.
In order to be helpful, search result clustering must organize similar results into one group. This is the primary requirement for all document clustering algorithms. But in search result clustering, the clusters labels are also extremely important. The program must accurately and concisely describe the cluster’s contents so that users can decide if the information is relevant.
Start with generic search terms first
Since users are often unaware of all their choices in a search, they do not always know the exact phrase they should search for. Thus, starting with a more generic search makes sense. Let the artificial intelligence of the Noggle search engine detect knowledge clusters based on the cross-document linguistic patterns. The visual guide then allows the user to quickly focus on the results of interest by visually selecting the relevant clusters.
This kind of interface for search results is implemented by applying a variety of document clustering techniques to the results returned. This is something that we call the Noggle “KnowledgeMap” and “ClusterSearch” technique.
The user can now select the cluster “Access Control” and browse the relevant documents from the initial request on “security”. And later focus in on the associated documents.
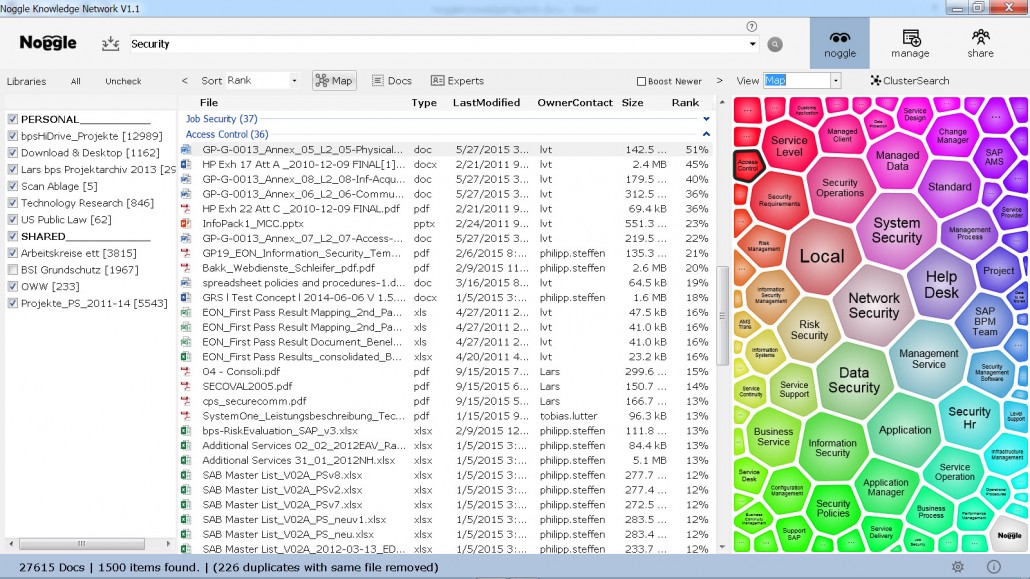
Figure 3: Document list in the security cluster “Access Control” from the overall search results
This makes document retrieval over different libraries and document search spaces much more efficient. By using “generic” search terms first, Noggle builds clusters for users, who can then narrow down their area of interest and check relevant documents there. Using Noggle this way is not just about searching for documents. Finally, it is a full, non-supervised knowledge management approach to retrieving knowledge that matters. Without the need to know exact phrases and exactly which documents they appear in.
Video Example
The following live presentation showcases the document clustering for included TED Talk digital library. All maps are build by the Noggle client based on the standard application (2min.):
[embedyt] http://www.youtube.com/watch?v=YMHxWGLddjE[/embedyt]
The NoggleMap feature combines latest technolgies based on Text parsing, Microsof Azure, Apache Lucene, Carrot2 Project, Noggle pre- and post-processing algorithms and the Noggle network. Patent pending.
Further Reading:


 anaged library-sharing feature enables organizations to make their documents retrievable by approved people through distributed-search functions. With this feature, users can easily and quickly retrieve useful, relevant documents stored elsewhere on the network or on local computers. The cross-library search saves time and helps avoid the high cost of reinventing the wheel when a document exists somewhere else but cannot be located locally. The embedded “request document” function makes knowledge sharing as simple and secure as sending emails. Cross-library searches speed up the retrieval process and make document retrieval a collaborative activity via our cognitive search engine.
anaged library-sharing feature enables organizations to make their documents retrievable by approved people through distributed-search functions. With this feature, users can easily and quickly retrieve useful, relevant documents stored elsewhere on the network or on local computers. The cross-library search saves time and helps avoid the high cost of reinventing the wheel when a document exists somewhere else but cannot be located locally. The embedded “request document” function makes knowledge sharing as simple and secure as sending emails. Cross-library searches speed up the retrieval process and make document retrieval a collaborative activity via our cognitive search engine.